
Humanitarian aid deduplication using blockchain technology
A blog by Samer Haffar, a Frontier Tech Hub Implementing Partner.
Pilot: De-duplicating aid to enhance the impact of humanitarian assistance
In this article, I’ll be explaining the work that we did in the fourth sprint of our pilot on the blockchain-based technology we proposed for addressing the humanitarian aid duplication problem in Nigeria. This is the fourth in a series of articles I previously published on the progress of the pilot. The first sprint of the pilot was all about raising awareness of the problem, announcing the pilot, gathering momentum, and encouraging humanitarian actors to participate in the pilot. In the second sprint, we engaged with humanitarian agencies and tackled the assumptions that we believe would motivate them to use the technology, namely: their data collection and management workflows, the use of biometrics, as well as compliance with data protection laws and regulations. In the third sprint, we onboarded the participating humanitarian agencies on the system and we worked together towards developing a shared standard for data collection and preprocessing something that is needed to make the technology work (Please check the How system works section below).
How the system works
In this section, I’m going to provide a quick reminder of how the system works just so that the rest of the article would make sense if you’re reading about our pilot for the first time. If you’re reading this after reading the previous articles (which I strongly recommend you do!), please skip this section and go right to the next one.
The GeniusChain system detects duplicate humanitarian aid by creating a Universal Unique Identifier (UUID) of each beneficiary and then using blockchain to record the aid that each beneficiary gets by all humanitarian agencies. Whenever an agency is to give aid to a beneficiary, it can use the system to check whether that beneficiary is getting duplicate aid (i.e., whether the beneficiary is already getting aid by other agencies). The great thing about this technology is that there’s no need to share beneficiary information with other agencies (including GeniusTags), because the entire duplication check operation is automated and is performed on top of blockchains. Sensitive data stays accessible only by each agency.
The UUIDs that are used for checking duplicates are generated by applying a hash function on beneficiary information that is collected by the agency. Thus, if agencies are collecting the same information about beneficiaries and the same beneficiary is registered twice, the system will generate the same UUID for the beneficiary in both cases, and thus flag a duplicate. UUIDs cannot be reverse engineered to recreate the beneficiary information, and only agencies with the same information can generate the same UUID, which guarantees the privacy and protection of beneficiary data. Although the use of hash functions for generating UUIDs guarantees privacy and security, it also makes UUIDs sensitive to the smallest change in the beneficiary information, i.e., changing even a single letter in that information would generate a completely different UUID. Therefore, there needs to be a shared standard for collecting and processing data to make sure the data used for generating the UUIDs is as standardized and consistent as possible. Please refer to section How system works in this article for a more detailed and step-by-step description.
Shared data standard
We asked the participating humanitarian agencies two questions. The first question was “what beneficiary information can we use to generate UIDs?” In the previous sprint, duplication checks were run only with the beneficiary’s first name, last name, gender, and whether there’s a disability in the household. In this sprint, we wanted to experiment with more data end points that would make the UIDs generated by the system even more unique to the beneficiary.
The second question was “what data cleaning and pre-processing rules would you like to configure the system to do on your behalf?” GeniusChain can automate a wide range of data pre-processing activities to ensure that the data used in generating the UIDs conforms to a shared standards for data consistency. The participating agencies decided that the following data about beneficiaries to be used for generating UIDs:
Beneficiary name
Beneficiary surname
Beneficiary gender
Next of kin name
Next of kin surname
Next of kin gender
Beneficiary’s community
For the data pre-processing rules, we built on the previous sprint results, and some discussions that happened during this sprint to come up with the following list of rules. These rules simply convert the different ways a name is written into a single standardized format. Thus, whenever any of those names occur in data, the system automatically converts them to their standardized writing. These rules were applied to the Beneficiary name, surname, next of kin name, next of kin surname.

Additionally, the following rules were defined for standardizing the genders (i.e., beneficiary gender, and next of kin gender) as follows:

Lastly, additional rules were configured to remove capitalizations and spaces before and after each data input.
Testing the system and coming up with the rules
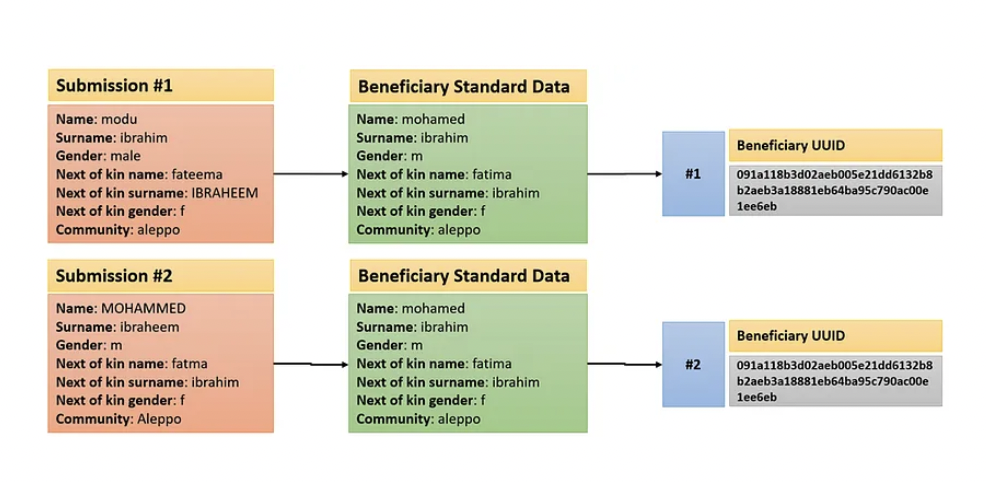
The participating agencies and the GeniusTags team tested the system on various combinations of beneficiary data to make sure that all the defined rules are working. While conducting those tests, the need for additional rules would arise and those would be added. An example of a beneficiary that the system can detect and flag as a duplicate is in the following figure. In the figure, you’ll see two submissions of beneficiary data and how the system converts this data into its standardized form, to then generate the same UUID for both submissions, which would then flag one of them as a duplicate.
Scalability and effectiveness
The extent to which the system is efficient and effective in detecting humanitarian aid duplication depends a lot on the consistency of the data used to generate UUIDs. Therefore, it is important that the standard for data collection and cleaning is comprehensive enough in terms of the data non-consistency cases they cover. There are three things that we learned about in this sprint in that regard, namely: how the platform can be used in the Nigerian context, how it can be scaled, and how the platform’s efficiency in detecting duplicates can be improved.
When we first started this sprint, the plan was to collaborate with the participating agencies to put together a standard for data collection and processing that the system can rely on to pre-process data into a consistent version that can then be used to generate beneficiary UUIDs, which are used for deduplications on the blockchain. So, we started with that, and arrived at a standard. Then, with each new test of the standard, the need for some new rules was identified and those rules were added to the standard. With more testing, we found that the need for new rules was diminishing, and that the standard was getting more mature in the sense that it was inclusive of most data pre-processing requirements for the Nigerian context. But then, if other agencies were to participate, the need for more rules would arise again because these new agencies bring their own data entry and processing practices to the platform that need to be considered for a consistent version of data. Of course, a lot of these practices would be identical to the ones already identified with the existing agencies (because all agencies are working in the same region, and are dealing with beneficiaries in the same context), but some would be new.
Upon reflecting on that, we concluded that developing a standard for ensuring data entry consistency is an ongoing process that never ends. At the start of developing such a standard, lots and lots of rules will be identified through the collaborative effort of all participating agencies. But as the platform gets more adoption by new agencies as well as existing ones, new rules for ensuring data consistency will be identified and added. If all agencies are working in the same context, they’re going to be dealing with beneficiaries that have a lot of similarities in culture and needs. Thus, the need for identifying new rules for data consistency decreases over time because chances are most of the data collection and practices of new agencies will have already been identified with existing ones, and rules for them were created. With enough agencies on board, a standard for data consistency that is comprehensive enough to cover most, if not all, the data pre-processing requirements that can bring all collected data to a consistent version.
With all that in mind, we can safely conclude that the platform: scales organically the more it gets adopted by participating agencies, and its effectiveness in detecting duplicate aid gets much better as it grows in terms of use by participating agencies.
Comparison between the Nigerian and Syrian contexts
Both the Nigerian and the Syrian contexts are similar in the sense that they both rely on personally identifying information to detect duplicates. However, there are the following differences:
In the Nigerian context, we relied on the personal information of the beneficiary’s next of kin; in the Syrian context, we only relied on the beneficiary’s own information (i.e., name, surname and gender) as well as their ID document.
In the Nigerian context, it is permitted to use biometrics for identifying beneficiaries; in the Syrian context, the use of biometrics is not allowed.
Identifying the requirements for scale in the Syria pilot was quicker because the platform had one of the participating agencies taking the lead on the data standard, the onboarding and the experimentation.
If you’d like to dig in further…
⛴️ Deep dive into the pilot’s learnings into beneficiary de-duplication in the Nigerian context — Data Management Workflows, Compliance with Data Protection Laws, and Use of Biometrics
⛴️ Explore learnings from the pilot’s first and third sprint